import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import minimize_scalar
from scipy.stats import norm
plt.rcParams["figure.figsize"] = (11, 5)The Besley and Case (1995) Model
Introduction
Besley and Case (1995) have a paper about the influence of term limits for politicians on policy behavior. They use a dynamic game. Politicians can serve either one or two periods, depending on whether they are retained. In these periods, politicians choose to put in effort. Putting in more or less effort is costly to different extents, according to their type. The chosen effort probabilistically affects a policy outcome. An infinitely-lived voter makes decisions to retain or dismiss the politician after observing the outcome. Their solution, based on Banks and Sundaram (1998) involves a cut-off equilibrium, with voters reelecting an incumbent politician if the probabilistically-influenced policy variable realization is higher than some threshold \(r_{min}\).
One of their key predictions is that the equilibrium amount of effort put in by politicians in their first period is higher than in their last period, irrespective of the politician’s type. The model predicts that the prospect of re-election incentivizes politicians to exert higher effort. Consequently, politicians in their first term will, on average, exert more effort and produce better policy outcomes than they will in their final term, when re-election is no longer a motivation. As Besley and Case put it:
If two terms are allowed, then incumbents who give higher first-term payoffs to voters are more likely to be retained to serve a second term. Those in their last term put in less effort and give lower payoffs to voters, on average, compared with their first term in office.
Their model is fairly general, so in this blog post, I wanted to give an easier-to-understand version for a specific case using Python to solve for some expressions that are not analytically soluble. I also want to demonstrate how to use standard computational techniques for this specific case.
Set-up
In the Besley and Case (1995) model, there can be \(k\) types of politicians, ordered by ability \(\omega_1 < \dots < \omega_k\). They occur with probabilities \(\pi_1, \dots, \pi_k\). In my setup, there are only two types, \(\omega_1 < \omega_2\) with \(\omega_1 = 3\) and \(\omega_2 = 9\), and a flat prior \(\pi_1 = \pi_2 = 1/2\). (With a very skewed prior toward the high type, the voter’s payoff from retention has so little room to grow above the no-screening level that the politicians’ equilibrium effort response can push \(W_0\) above the natural ceiling and no pure-strategy cutoff equilibrium exists. A balanced prior keeps the example clean.) The politician’s per-period utility is:
\[ v(\alpha, \omega_i) = \alpha - \frac{\alpha^2}{\omega_i} \]
If the politician is in power, otherwise, utility is zero. This reflects a reward proportional to effort, while effort is also costly (utility is quadratic in effort), with the cost being lower for higher-quality types.
Effort is mapped into policy outcomes, \(r\), probabilistically via \(F(\alpha, r)\). In the Besley and Case (1995) setting, this can be any distribution satisfying the monotone likelihood ratio property. In my setting, I take the outcome distribution to be Normal, meaning \(R \sim \mathcal{N}(\alpha, 1)\). The voter’s one-period utility is simply the realized outcome \(r\).
Optimization of the politician
In the second (and final) period, the politician faces no re-election incentive and will simply optimize their one-period utility by choosing effort \(\alpha\): \[ \max_{\alpha} \left( \alpha - \frac{\alpha^2}{\omega_i} \right) \]
The first-order condition is \(1 - \frac{2\alpha}{\omega_i} = 0\), which yields the optimal second-period effort:
\[ a^s_i = \frac{\omega_i}{2} \]
In the first period, the politician chooses effort to maximize their current utility plus the discounted expected utility from a potential second term:
\[ a^l_i = \arg\max_{\alpha} \left\{ v(\alpha, \omega_i) + \delta \cdot \text{Pr}(\text{re-election} | \alpha) \cdot v(a^s_i, \omega_i) \right\} \]
Given the voter’s retention rule, the probability of re-election is the probability that the realized outcome \(r\) is greater than the voter’s retention threshold, \(\text{Pr}(r > r_{\min} | \alpha)\).
Optimization of the voter
After observing the realized outcome \(r\) after one period, the voter updates their belief that the incumbent is the low type (\(\omega_1\)) using Bayes’ rule:
\[ \beta_1(r) = \frac{\pi_1 \cdot f(r | a^l_1)}{\pi_1 \cdot f(r | a^l_1) + \pi_2 \cdot f(r | a^l_2)} \]
The expected utility to the voter of retaining the incumbent for a second period is the belief-weighted average of the expected outcomes from each type’s second-period effort:
\[ v_2(r) = \beta_1(r) \cdot E[\hat{r} | a^s_1] + (1 - \beta_1(r)) \cdot E[\hat{r} | a^s_2] \]
Since utility is linear in \(r\) and \(E[\hat{r} | a^s_i] = a^s_i\), this simplifies to:
\[ v_2(r) = \beta_1(r) \cdot a^s_1 + (1 - \beta_1(r)) \cdot a^s_2 \]
Banks and Sundaram (1993) show that the Bellman equation for the voter’s problem when facing an incumbent who has served one term is:
\[ W(1, r, p) = \max \left\{ v_2(r) + \delta W(0, \pi), W(0, \pi) \right\} \]
The first term inside the max is the value of retaining the incumbent, and the second is the value of dismissing them and drawing a new politician. The state vector is {term, r, beliefs}. Here, term=1 means the incumbent can serve one more term. \(W(0, \pi)\) represents the value of drawing a new politician, where beliefs are reset to the prior probabilities \(\pi\).
The Bellman equation for the state \(W(0, \pi)\), the value of drawing a fresh politician, is the expected immediate reward from that new politician’s first term, plus the discounted continuation value:
\[ W(0, \pi) = \sum_{i=1}^2 \pi_i \cdot E[\hat{r} | a^l_i] + \delta \int W(1, \hat{r}, \beta_1(\hat{r})) \left( \sum_{k=1}^2 \pi_k \cdot f(\hat{r} | a^l_k) \right) d\hat{r} \]
Note that the efforts used here must be the first-period efforts, \(a^l_k\), as this state represents the start of a new politician’s potential two-term tenure. So what is this? In simple terms, \(W(0, \pi)\) is the voter’s total expected lifetime utility from the moment they decide to bring in a new, unknown politician.
This situation arises in two scenarios:
- The voter dismisses an incumbent after their first term.
- An incumbent has finished their second and final term, and a new election must be held.
The equation defines this value recursively, following the fundamental principle of dynamic programming: “The value of a decision today is the immediate reward you get plus the discounted value of the best situation you can be in tomorrow.”
- \(W(...)\): This is the Value Function. It represents the maximum expected lifetime utility for the voter, starting from a specific state.
- \(0\): This is the first element of the state vector, representing the number of re-election terms an incumbent has remaining. A \(0\) here signifies that we are not evaluating an incumbent. Instead, we are at a “clean slate” moment—the value of drawing a new politician who will start their first term.
- \(\pi\): This represents the voter’s beliefs. Since the politician is a fresh draw from the pool of candidates, the voter has no performance information yet. Their belief about the politician’s type is simply the objective prior probability distribution, \(\pi = (\pi_1, \pi_2)\) (in our example, a 50/50 chance of each type).
So, \(W(0, \pi)\) reads as “The value to the voter of being in a state where a new politician is about to be drawn, and beliefs about this politician are the priors \(\pi\).”
The RHS is composed of two main parts, representing “what I get now” and “what I get later.”
\[ \sum_{i=1}^2 \pi_i \cdot E[\hat{r} | a^l_i] \]
This term calculates the expected utility the voter will receive in the very next period from this new politician.
- \(\pi_i\): The probability that the new politician is of type \(i\).
- \(a^l_i\): The optimal first-period effort that a politician of type \(i\) will exert. It is critically important that this is \(a^l\) (first-period effort) and not \(a^s\) (second-period effort), because this new politician has a re-election incentive and will adjust their behavior accordingly.
- \(E[\hat{r} | a^l_i]\): The expected policy outcome \(\hat{r}\) (and thus the voter’s expected utility, since it’s linear) given that the politician exerts effort \(a^l_i\). In the specific model where \(r \sim \mathcal{N}(\alpha, 1)\), this expected value is simply \(a^l_i\).
- \(\sum\) (Summation): The voter doesn’t know the type of the new politician. The summation takes the average of the expected outcomes, weighted by the probability of drawing each type.
The voter thinks, “With probability \(\pi_1\), I’ll get a low-ability politician who will give me an expected outcome of \(a^l_1\). With probability \(\pi_2\), I’ll get a high-ability politician who will give me \(a^l_2\). My expected utility for this first period is the average of those two possibilities.”
\[ \delta \int W(1, \hat{r}, \beta_1(\hat{r})) \left( \sum_{k=1}^2 \pi_k \cdot f(\hat{r} | a^l_k) \right) d\hat{r} \]
This term represents the value of all subsequent periods, starting from the period after the new politician’s first term.
\(\delta\): The voter’s discount factor (\(0 < \delta < 1\)). Future utility is worth less than present utility, and \(\delta\) captures this time preference.
\(\int \dots d\hat{r}\) (The Integral): The voter knows that some outcome \(\hat{r}\) will be realized, but they don’t know what it will be. The integral sums up the value across all possible continuous outcomes \(\hat{r}\), weighting each by its probability of occurring.
Let’s break down the two components inside the integral:
- The Future Value \(W(1, \hat{r}, \beta_1(\hat{r}))\):
- This is the value of the state the voter will be in after observing the outcome \(\hat{r}\).
- \(1\): The state has transitioned. The politician has served one term and now has one re-election term remaining.
- \(\hat{r}\): The specific outcome that was realized. This is now known history and is part of the new state.
- \(\beta_1(\hat{r})\): The voter’s updated belief (the posterior probability) that the politician is low-ability, calculated using Bayes’ rule after observing \(\hat{r}\). A high \(\hat{r}\) will lower this belief, making the voter more optimistic about the incumbent. The future value heavily depends on this belief.
- The Probability Weight \(( \sum_{k=1}^2 \pi_k \cdot f(\hat{r} | a^l_k) )\):
- This term is the probability density function of observing the outcome \(\hat{r}\). It’s the overall likelihood of a specific \(\hat{r}\) happening.
- It’s calculated using the Law of Total Probability: The total probability of seeing \(\hat{r}\) is (the probability of drawing type 1 \(\times\) the probability that type 1 produces \(\hat{r}\)) + (the probability of drawing type 2 \(\times\) the probability that type 2 produces \(\hat{r}\)).
The voter thinks, “After the first period, some outcome \(\hat{r}\) will occur. For any given \(\hat{r}\), I’ll update my beliefs and be faced with a new problem: whether to keep or dismiss this incumbent, a state which has value \(W(1, \hat{r}, \beta_1(\hat{r}))\). To find the expected value of the future, I must average the values of all these possible future states, weighting each by the probability that the \(\hat{r}\) leading to it actually happens. Finally, I’ll discount this entire future prospect by \(\delta\).”
Putting it all together, the Bellman equation \(W(0, \pi)\) establishes the “outside option” or “reset value” for the voter. Whenever the voter considers dismissing an incumbent, they compare the value of keeping them against the value of starting fresh, which is exactly \(W(0, \pi)\).
Now that we have the Bellman equations, we can use value-function iteration to find the voter’s optimal retention rule.
Implementation
Below, I load the necessary libraries and define a Python class RetentionModel to hold the model’s parameters and methods.
class RetentionModel:
def __init__(self, delta=0.95, types=(3, 9), types_freq=(0.5, 0.5)):
self.delta = delta
self.types = np.array(types, dtype=float)
self.types_freq = np.array(types_freq, dtype=float)
# Grid over realized outcomes r, wide enough to cover essentially
# all probability mass for the relevant effort levels (a ~ 1.5–5.5,
# standard deviation 1).
self.r_grid = np.linspace(-3.0, 15.0, 401)
def f(self, r, effort):
"""Normal PDF of r given effort."""
return norm.pdf(r, loc=effort, scale=1.0)
def F(self, r, effort):
"""Normal CDF of r given effort."""
return norm.cdf(r, loc=effort, scale=1.0)
def effort_second_period(self, typ):
"""Optimal last-term effort: ω_i / 2."""
return typ / 2.0
def politician_value(self, effort, typ, retention_r):
"""First-period objective: flow utility plus discounted expected
second-term utility, weighted by the probability of re-election."""
a_s = self.effort_second_period(typ)
v_s = a_s - a_s**2 / typ # = typ / 4
prob_reelect = 1.0 - self.F(retention_r, effort)
return effort - effort**2 / typ + self.delta * prob_reelect * v_s
def effort_first_period(self, typ, retention_r):
"""Optimal first-period effort given type and retention threshold."""
obj = lambda a: -self.politician_value(a, typ, retention_r)
res = minimize_scalar(obj, bounds=(1e-9, typ), method='bounded')
return res.x
def beta_1(self, r, a1_l, a2_l):
"""Posterior probability that the incumbent is the low type, given
the equilibrium first-period efforts (a1_l, a2_l)."""
num = self.types_freq[0] * self.f(r, a1_l)
denom = num + self.types_freq[1] * self.f(r, a2_l)
# Where the denominator underflows to zero, the prior is the limit.
safe_denom = np.where(denom > 0, denom, 1.0)
return np.where(denom > 0, num / safe_denom, self.types_freq[0])
def v_2(self, r, a1_l, a2_l):
"""Voter's expected next-period payoff from retaining the incumbent."""
beta1_r = self.beta_1(r, a1_l, a2_l)
a1_s = self.effort_second_period(self.types[0])
a2_s = self.effort_second_period(self.types[1])
return beta1_r * a1_s + (1 - beta1_r) * a2_sTwo simplifications keep the implementation small. First, the voter’s continuation value when no incumbent is in office, \(W(0, \pi)\), does not depend on any observed outcome — it is just a scalar, which we’ll call \(W_0\). Second, when an incumbent has one term left the voter’s posterior belief is a deterministic function of \(r\) (given equilibrium first-period efforts), so we don’t need beliefs as a separate state variable. The state \((1, r)\) already encodes everything the voter knows, and the incumbent value function collapses to
\[ W_1(r) = \max\bigl\{ v_2(r) + \delta W_0,\; W_0 \bigr\}, \]
which is a one-dimensional object. The retention rule is the cutoff that makes the voter indifferent: \(v_2(r_{\min}) = (1 - \delta)\, W_0\).
Value Function Iteration
The equilibrium is the joint fixed point of three relationships: politicians’ first-period efforts respond to the cutoff \(r_{\min}\); the voter’s \(W_0\) responds to those efforts and the cutoff; and \(r_{\min}\) in turn is pinned down by \(v_2(r_{\min}) = (1-\delta)\,W_0\). We split the problem into two nested loops:
- an inner loop that solves the contraction \(W_0 = \mathbb{E}[a^l] + \delta\,\mathbb{E}\bigl[\max(v_2(r) + \delta W_0,\, W_0)\bigr]\) for fixed politicians’ efforts; and
- an outer loop that updates \(r_{\min}\) from the cutoff condition once \(W_0\) has converged.
model = RetentionModel(delta=0.95)def solve_W0(model, a1_l, a2_l, tol=1e-10, max_iter=2000):
"""Inner VFI: given fixed first-period efforts, solve the scalar
fixed point W_0 = E[a^l] + delta * E[max(v_2(r) + delta W_0, W_0)].
This map is a contraction with modulus delta^2, so it converges
geometrically."""
r_grid = model.r_grid
v2_r = model.v_2(r_grid, a1_l, a2_l)
g_r = (model.types_freq[0] * model.f(r_grid, a1_l)
+ model.types_freq[1] * model.f(r_grid, a2_l))
immediate = model.types_freq[0] * a1_l + model.types_freq[1] * a2_l
W0 = immediate / (1 - model.delta) # bounding initial guess
for _ in range(max_iter):
W1 = np.maximum(v2_r + model.delta * W0, W0)
W0_new = immediate + model.delta * np.trapezoid(W1 * g_r, r_grid)
if abs(W0_new - W0) < tol:
return W0_new, v2_r
W0 = W0_new
return W0, v2_r
def implied_cutoff(model, v2_r, W0):
"""Smallest r at which retaining the incumbent beats dismissing them,
i.e. v_2(r) >= (1 - delta) * W_0. v_2 is monotone increasing in r
under MLRP, so the cutoff is unique. We interpolate linearly between
the two grid points that bracket the crossing."""
cross = v2_r - (1 - model.delta) * W0
above = cross >= 0
if not above.any():
return model.r_grid[-1]
idx = int(np.argmax(above))
if idx == 0:
return model.r_grid[0]
r0, r1 = model.r_grid[idx - 1], model.r_grid[idx]
c0, c1 = cross[idx - 1], cross[idx]
return r0 - c0 * (r1 - r0) / (c1 - c0)def solve(model, tol=1e-7, max_iter=200, verbose=True, print_skip=2):
"""Outer iteration: alternate (best-response efforts) -> (W_0) -> (r_min)
until the cutoff stops moving."""
r_min = 3.0
for i in range(1, max_iter + 1):
a1_l = model.effort_first_period(model.types[0], r_min)
a2_l = model.effort_first_period(model.types[1], r_min)
W0, v2_r = solve_W0(model, a1_l, a2_l)
r_min_new = implied_cutoff(model, v2_r, W0)
err = abs(r_min_new - r_min)
r_min = r_min_new
if verbose and i % print_skip == 0:
print(f"outer {i:3d}: err = {err:.2e}, "
f"r_min = {r_min:.5f}, W0 = {W0:.4f}")
if err < tol:
if verbose:
print(f"\nConverged in {i} outer iterations.")
return {"r_min": r_min, "W0": W0, "a1_l": a1_l, "a2_l": a2_l}
print("Failed to converge!")
return {"r_min": r_min, "W0": W0, "a1_l": a1_l, "a2_l": a2_l}Solution
The procedure converges and the model is solved.
out = solve(model)outer 2: err = 1.17e-01, r_min = 3.75279, W0 = 75.3843
outer 4: err = 1.01e-02, r_min = 3.79688, W0 = 75.9659
outer 6: err = 1.04e-03, r_min = 3.80115, W0 = 76.0191
outer 8: err = 1.06e-04, r_min = 3.80159, W0 = 76.0246
outer 10: err = 1.09e-05, r_min = 3.80164, W0 = 76.0252
outer 12: err = 1.12e-06, r_min = 3.80164, W0 = 76.0252
outer 14: err = 1.15e-07, r_min = 3.80164, W0 = 76.0252
Converged in 15 outer iterations.The optimal retention rule \(r_{\min}\), the scalar value \(W_0\), and the equilibrium efforts are:
a1_s = model.effort_second_period(model.types[0])
a2_s = model.effort_second_period(model.types[1])
print(f"Optimal retention threshold r_min : {out['r_min']:.4f}")
print(f"Voter's outside-option value W_0 : {out['W0']:.4f}")
print(f"First-period effort (low, high) : ({out['a1_l']:.4f}, {out['a2_l']:.4f})")
print(f"Second-period effort (low, high) : ({a1_s:.4f}, {a2_s:.4f})")Optimal retention threshold r_min : 3.8016
Voter's outside-option value W_0 : 76.0252
First-period effort (low, high) : (1.5325, 5.4639)
Second-period effort (low, high) : (1.5000, 4.5000)This is an interior solution to the problem. As predicted by the model, first-period efforts strictly exceed second-period efforts for both types: the prospect of re-election disciplines politicians. We can visualize the cutoff by plotting \(v_2(r)\) against the threshold \((1-\delta)W_0\):
r_plot = np.linspace(-1, 9, 400)
v2_plot = model.v_2(r_plot, out['a1_l'], out['a2_l'])
threshold = (1 - model.delta) * out['W0']
fig, ax = plt.subplots()
ax.plot(r_plot, v2_plot, label=r"$v_2(r)$")
ax.axhline(threshold, color="grey", linestyle="--",
label=r"$(1-\delta)\,W_0$")
ax.axvline(out['r_min'], color="red", linestyle=":",
label=fr"$r_{{\min}} = {out['r_min']:.3f}$")
ax.set_xlabel("Observed outcome $r$")
ax.set_ylabel("Value to voter")
ax.legend()
plt.show()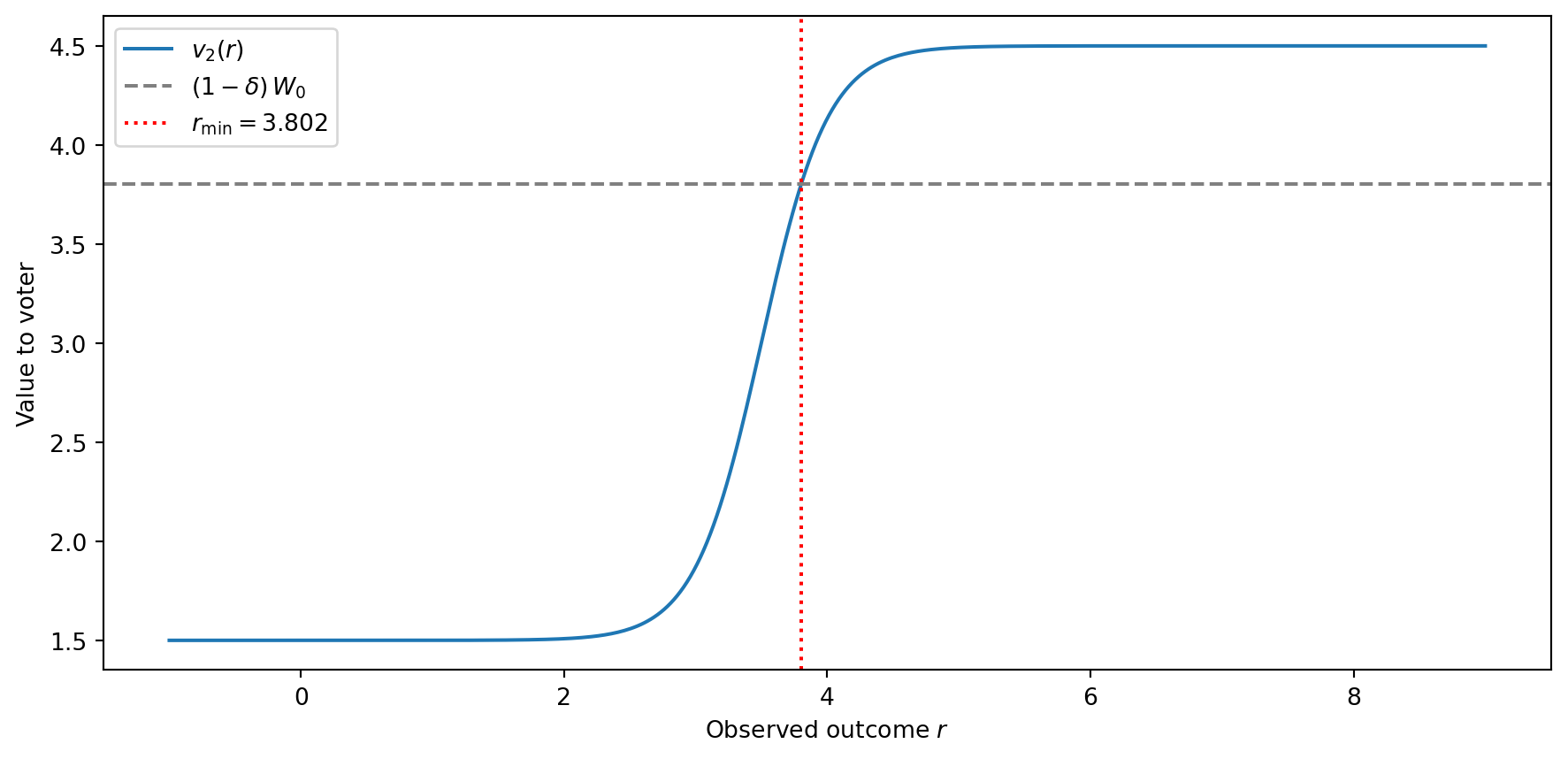
This solution characterizes a cut-off rule, as described by Banks and Sundaram (1993): the voter retains the incumbent if and only if the observed outcome \(r\) is above \(r_{\min}\).
I hope this has been useful! If you have any tips or remarks, let me know, and thanks for reading.