Spatial Merging Roman Roads with Eurostat Data
February 15, 2023
Introduction
In this short blog post, I focus on combining several European municipal (LAU, Local Urban Areas) shapefiles, combined with data on roads and cities in the Roman Empire, to find relationships between present-day outcomes and deep-routed interventions as far as more than 2000 years ago.
Let us first load the libraries we need to perform operations.
library(tidyverse)
library(giscoR)
library(sf)
library(cawd)
library(regions)
For robustness, and out of curiosity, I will use two roads files. One of them is in the cawd package, and contains roads that existed at about 200AD:
roads <- cawd::darmc.roman.roads.major.sp |> st_as_sf()
The other is found here, which is derived from the Barrington Atlas of the Greek and Roman World.
roads_alt <- read_sf("~/Downloads/shp_roads/ba_roads.shp")
I’ll also use data on Roman cities, from here.
url <- 'http://oxrep.classics.ox.ac.uk/oxrep/docs/Hanson2016/Hanson2016_Cities_OxREP.csv'
download.file(url, destfile = 'roman_cities.csv')
cities <- read_csv('roman_cities.csv')
For the contemporary regional data, we first have to know what the NUTS system is.
The Nomenclature of Territorial Units for Statistics (NUTS) is a classification system developed by Eurostat, the statistical office of the European Union. It provides a hierarchical system of administrative units for statistical purposes, based on a harmonized division of the European territory. The NUTS classification is used for the collection, development, and harmonization of European regional statistics, and it is the standard for reporting regional data to the European Union.
The NUTS classification consists of three hierarchical levels:
- NUTS 1: major socio-economic regions
- NUTS 2: basic regions for the application of regional policies
- NUTS 3: small regions for specific diagnoses and analyses
Each level is defined based on a combination of administrative and geographical criteria, and the classification is regularly updated to reflect changes in the administrative boundaries of European countries.
Beyond the lowest NUTS level, there are also yet smaller subdivisions. The LAU classification system consists of two levels:
- LAU 1: level of the larger administrative units, which can be either a municipality or a group of municipalities that form a joint authority
- LAU 2: level of the smaller administrative units, which correspond to individual municipalities or local authorities
In this blog, I’ll be using shapefiles at the LAU1 level. The shapefiles at the LAU level can be downloaded with the help of the giscoR package, an interface to the API of Eurostat. Alternatively, it is available
here. Let us first focus on France and Germany, for simplicity.
lau <- giscoR::gisco_get_lau(year = '2019', country = c("Germany" , "France"))
Cleaning the maps
We need to exclude the overseas territories of France. Let us do that:
xmin <- -10
xmax <- 20
ymin <- 40
ymax <- 80
box <- st_bbox(c(xmin=xmin, xmax=xmax, ymax=ymax, ymin=ymin), crs = st_crs(4326))
square <- st_sf(st_as_sfc(box))
fr_gr <- st_intersection(lau, square)
fr_gr |> ggplot() + geom_sf()
Bringing the data together
Since the data should be in the same projection, we should check that:
st_crs(fr_gr) == st_crs(roads)
## [1] TRUE
.. and it should be possible to merge the datasets together. This can be done by bind_rows, but we want to make sure that the geometry variables are under one variable:
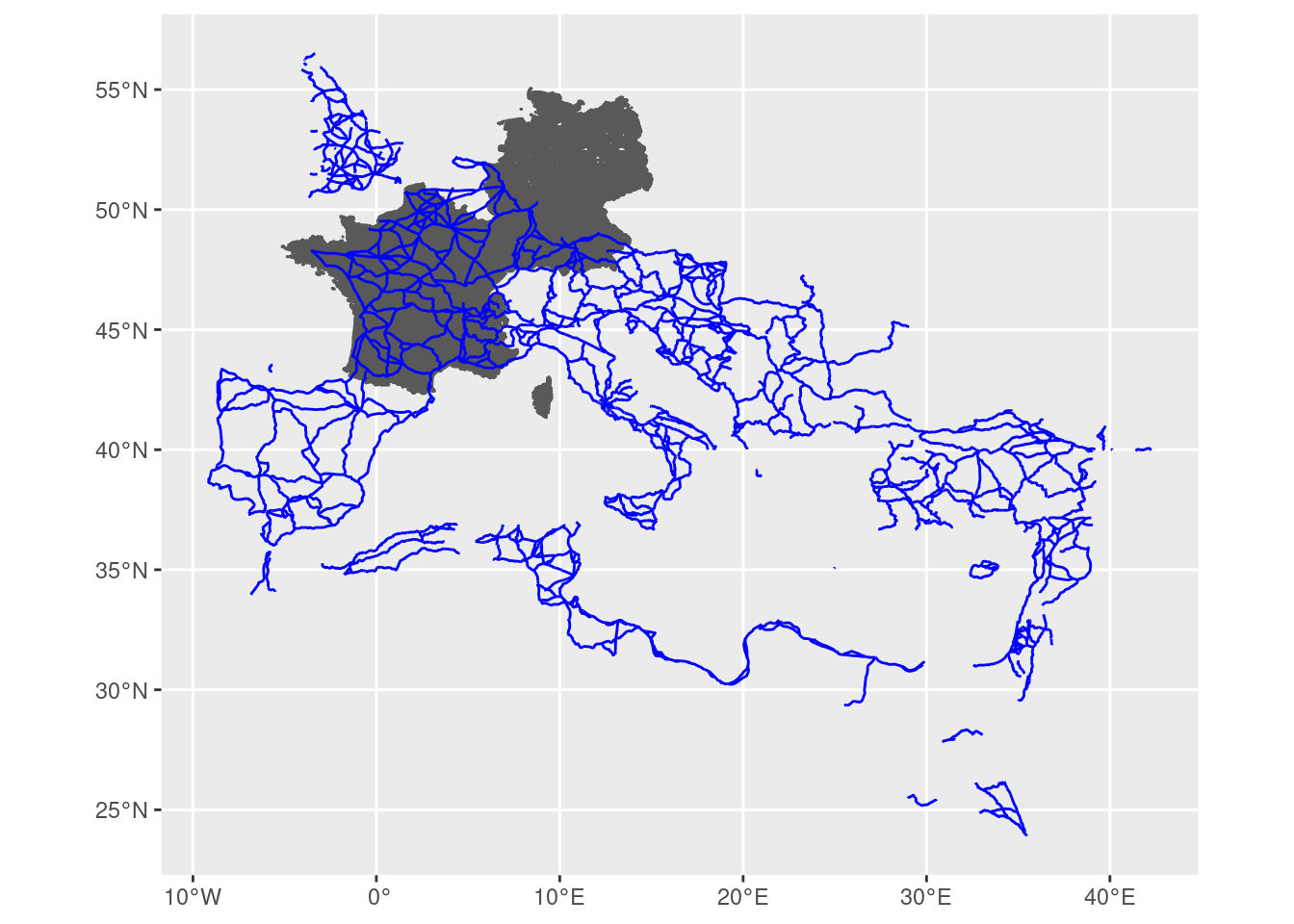
lau_roads <- bind_rows(fr_gr |> rename(geometry = `_ogr_geometry_`), roads)
ggplot() + geom_sf(data = lau_roads |> filter(!is.na(id))) +
geom_sf(data = lau_roads |> filter(!is.na(OBJECTID)), color = 'blue')
In the roads data.frame, we might also want to focus on France and Germany, rather than on all roads in the former Roman empire.
roads_in_fr_gr <- st_intersects(roads, fr_gr)|>
as.data.frame() |>
select(row.id) |>
pull() |>
unique()
roads2 <- roads |> filter(is.element(row_number(), roads_in_fr_gr))
lau_roads2 <- bind_rows(fr_gr |> rename(geometry = `_ogr_geometry_`), roads2)
ggplot() + geom_sf(data = lau_roads2 |> filter(!is.na(id))) +
geom_sf(data = lau_roads2 |> filter(!is.na(OBJECTID)), color = 'blue')
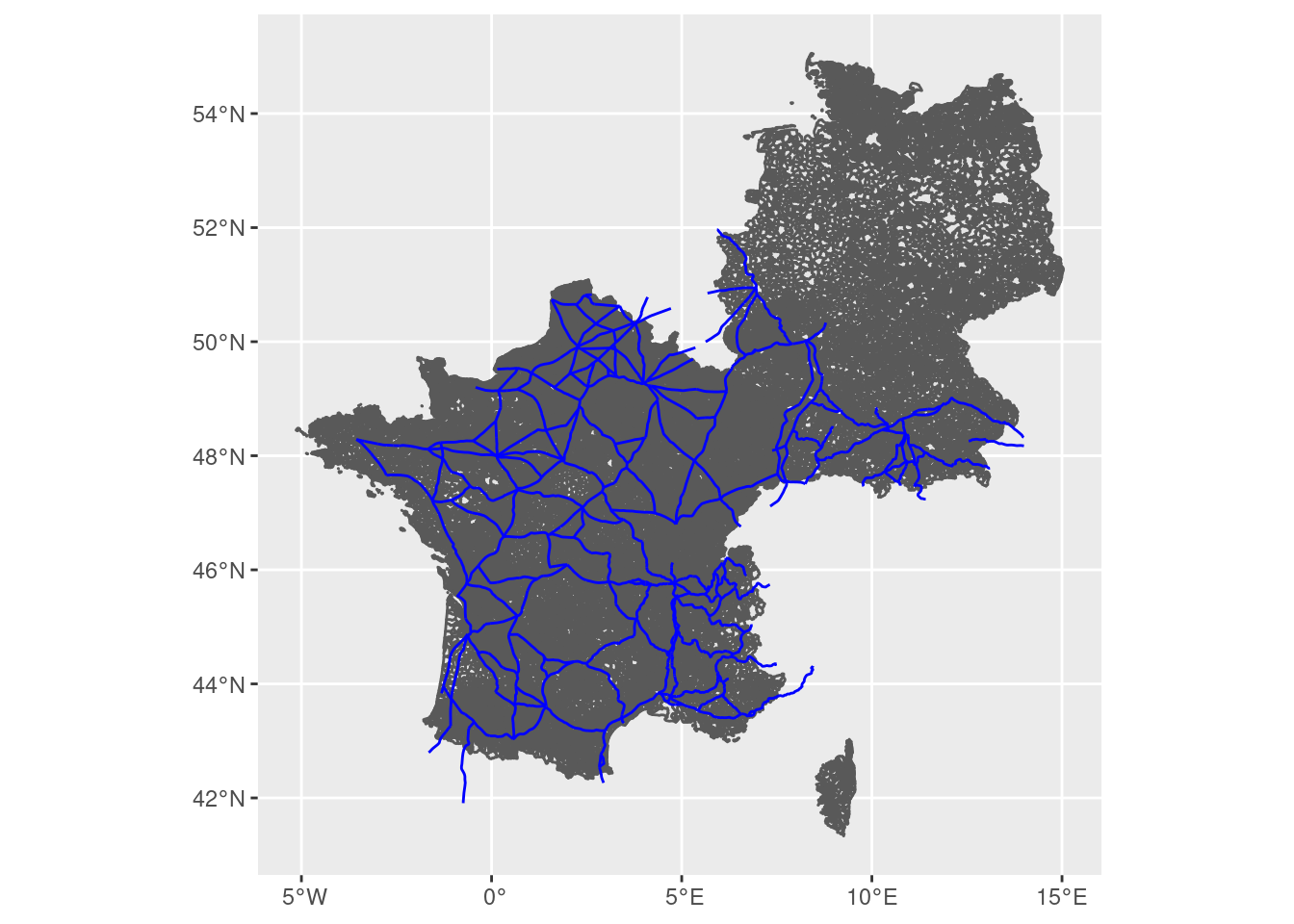
Now we have obtained a nice map of Roman roads in Germany and France, and we can do some spatial data manipulation to calculated the minimum distances of the centroid of each of these communes to the Roman roads. This can be the basis of a regression design attempting to investigate the persistent impact of these roads.
We also might want to use NUTS or higher-level classifications of areas, for which we need a table that goes from LAU to NUTS3. We can use the region package to get access to such a table:
nuts_lau_table <- regions::nuts_lau_2019 |>
filter(is.element(country, c("DE", "FR"))) |>
select(code_2016, lau_code)
And possibly, from NUTS3 to NUTS, where we’ll be using that a NUTS3 area should be within a NUTS2 area. In the end, we thus expect to have a data.frame with 497 observations (the no. of observations in the NUTS3 data.frame), with each observation being linked to one NUTS2 area in which it is located:
countries <- data.frame(country = c("Germany", "France"), year = rep(2019, 2), geo = c("DE", "FR"), values = c(1,99))
nuts_table <- regions::impute_down_nuts(countries) |>
filter(typology == 'nuts_level_2')
nuts_2_3_conversion_table <- regions::impute_down_nuts(nuts_table)
nuts_2_3_conversion_table <- nuts_2_3_conversion_table |>
filter(typology == 'nuts_level_3') |>
mutate(method = str_extract(pattern = '\\b\\w+\\b$', method)) |>
rename(nuts_2 = method, nuts_3 = geo) |>
select(nuts_3, nuts_2)
And finally, we merge them together with the nuts_lau_table key, so we know for every LAU-area, the corresponding NUTS2 and NUTS3 levels. We then only need the conversion table, to display the map at different NUTS/LAU levels: we can again display the shapefile by merging all the polygons within a certain NUTS3 or NUTS2 area.
nuts_lau_table <- nuts_lau_table |>
left_join(nuts_2_3_conversion_table, by = c('code_2016' = 'nuts_3')) |>
rename(nuts_3 = code_2016)
After merging with the lau_roads2 dataset, we can subsequent restrict our analysis to the NUTS2 or NUTS3 areas that have any roads in it at all (or alternatively, that were part of the Roman Empire):
lau_roads2 <- lau_roads2 |> left_join(nuts_lau_table, by = c("LAU_ID" = "lau_code"))
Now, we can plot on either LAU, NUTS3, or NUTS2 level. I’ll opt for the NUTS3 option here to illustrate:
lau_roads2 |>
filter(!is.na(LAU_ID)) |>
group_by(nuts_2) |>
summarize(geometry = st_union(geometry)) |>
ggplot() + geom_sf()
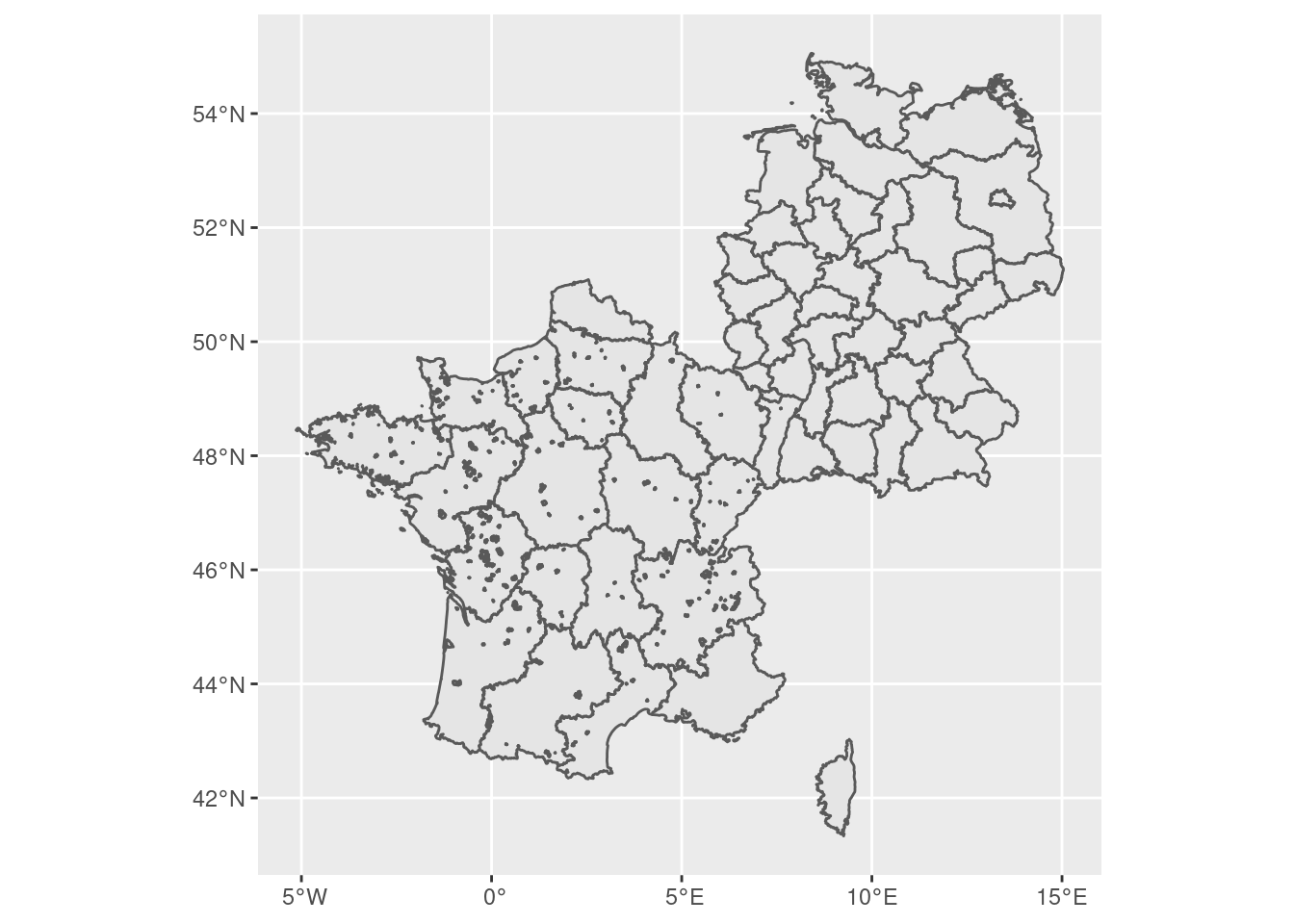
#nuts_2 |> ggplot() + geom_sf()
Bar a couple of small inaccuracies, everything seems to be consistent between the indices at these levels.
Alternative way
An alternative way is to use a manual approach based on geographical intersections between municipalities of higher and lower levels. It turns out that the NUTS-administration way as described above is best for Germany, while the more manual geographical intersections approach is best for France. Let me therefore do Germany and France separately. Germany is already done above, and France follows below:
germany <- lau_roads2 |> filter(CNTR_CODE == "DE") |> select(-c(OBJECTID:Shape_Leng))
# Unselect the LAU-NUTS3-NUTS2 table as constructed above, and get one manually
france_lau <- lau_roads2 |> filter(CNTR_CODE == "FR") |> select(-c(nuts_2, nuts_3), -c(OBJECTID:Shape_Leng))
# Retrieve the map on a NUTS 3 level
fr_nuts_3 <- giscoR::gisco_get_nuts(year = "2016", country = "France", nuts_level = 3)
# Spatial merge the two
fr_lau_and_3 <- st_join(france_lau, fr_nuts_3) |>
group_by(LAU_ID) |>
slice(1)
fr_lau_and_3 |>
group_by(NUTS_ID) |>
summarize(geometry = st_union(geometry)) |>
ggplot() + geom_sf()
And now we could repeat the trick again, but simply using the table also gets us to NUTS2 easily and without loss of accuracy:
france <- fr_lau_and_3 |>
left_join(nuts_2_3_conversion_table, by = c("NUTS_ID" = "nuts_3")) |>
rename(nuts_3 = NUTS_ID, CNTR_CODE = CNTR_CODE.y, FID = FID.y)
france |>
group_by(nuts_2) |>
summarize(geometry = st_union(geometry)) |>
ggplot() + geom_sf()
Nice! Now we can put France and Germany back together again:
cols <- germany |> colnames()
france <- france |> select(cols)
fr_gr <- bind_rows(france, germany)
Filter the map
For the analysis, we might only want to include LAU’s in NUTS2-areas that contain a road at all. Let’s try to do that first.
frgrn2 <- fr_gr |>
group_by(nuts_2) |>
summarize(geometry = st_union(geometry))
nos <- st_intersects(frgrn2, roads2) |>
as.data.frame() |>
select(row.id) |>
pull() |>
unique()
include <- frgrn2$nuts_2[nos]
final <- fr_gr |>
filter(is.element(nuts_2, include))
Now, we have a data.frame with only the NUTS2 regions that actually have roads. This way, we only compare regions that are “fairly close” to wherever the Roman empire’s borders stretched. Now it’s time to do some computation and analysis!
Analysis
Suppose we want to know whether the distance of a present-day LAU (municipality, say) exhibits persistent effects of being close to a Roman road. I will present two ways in which you can analyze the question. Firstly, I will use all possible municipalities and find out if the distance to a road is related to economic development in terms of present-day population density.
Secondly, I will use a “treatment” and “control” group, the first consisting of municipalities in which an ancient Roman road stretched, the other consist of municipalities bordering this municipalities, but in which no road was built. This makes sure you compare very similar municipalities, where you compare places in which the Roman built roads to places in which the Romans could have built roads, but didn’t.
First way
We simply compute the closest distance to a Roman road for each of the observations in final.
distance_matrix <- final|>
st_distance(roads2)
distance_matrix <- st_distance(st_centroid(final), roads2)
minimum_distances <- apply(distance_matrix, 1, min)
final <- final |>
mutate(min_dist_to_road = minimum_distances)
Let us plot this in conjunction with the roads to see if it’s correct:
ggplot() + geom_sf(data = final, aes(fill = min_dist_to_road), size = 0.01) + geom_sf() +
geom_sf(data = roads2, color = 'orange')
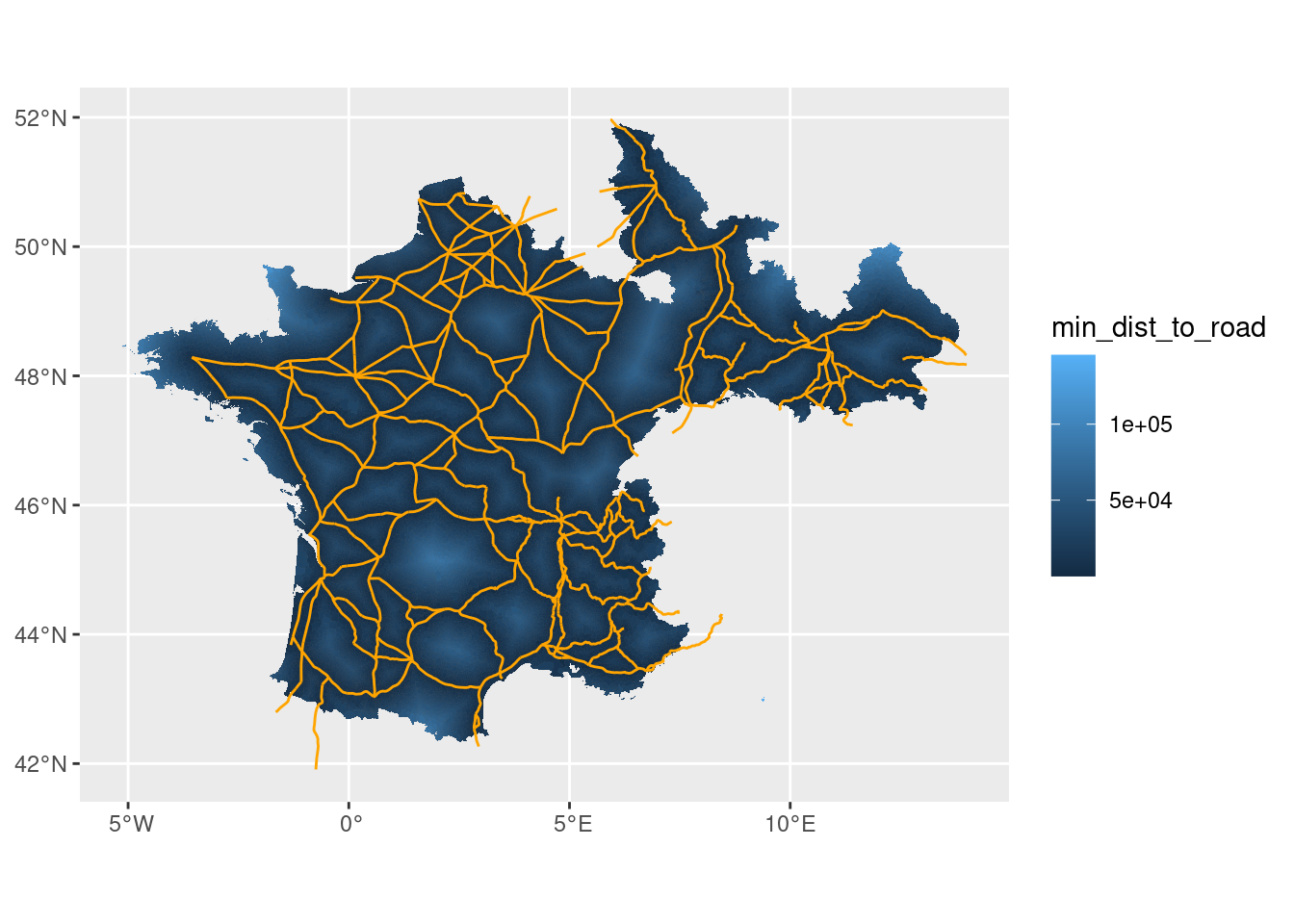
Let’s now do a small analysis on the variable of population density, a variable readily available in the dataset.
library(modelsummary)
library(fixest)
model1 <- fixest::feols(POP_DENS_2019 ~ min_dist_to_road, final)
model2 <- fixest::feols(POP_DENS_2019 ~ min_dist_to_road | nuts_3, final)
model3 <- fixest::feols(POP_DENS_2019 ~ min_dist_to_road | nuts_3 + nuts_2, final)
model4 <- fixest::feols(POP_DENS_2019 ~ min_dist_to_road | nuts_3 + nuts_2 + CNTR_CODE, final)
model5 <- fixest::feols(POP_DENS_2019 ~ min_dist_to_road | nuts_3^nuts_2, final)
model6 <- fixest::feols(POP_DENS_2019 ~ min_dist_to_road | nuts_3^nuts_2^CNTR_CODE, final)
modelsummary(list(model1, model2,
model3, model4,
model5, model6), stars = T)
| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 | |
|---|---|---|---|---|---|---|
| (Intercept) | 232.232*** | |||||
| (5.025) | ||||||
| min_dist_to_road | −0.004*** | −0.003*** | −0.003*** | −0.003*** | −0.003*** | −0.003*** |
| (0.000) | (0.001) | (0.001) | (0.001) | (0.001) | (0.001) | |
| Num.Obs. | 39973 | 39906 | 39906 | 39906 | 39906 | 39906 |
| R2 | 0.007 | 0.580 | 0.580 | 0.580 | 0.580 | 0.580 |
| R2 Adj. | 0.007 | 0.577 | 0.577 | 0.577 | 0.577 | 0.577 |
| R2 Within | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | |
| R2 Within Adj. | 0.005 | 0.005 | 0.005 | 0.005 | 0.005 | |
| RMSE | 692.67 | 450.45 | 450.45 | 450.45 | 450.45 | 450.45 |
| Std.Errors | IID | by: nuts_3 | by: nuts_3 | by: nuts_3 | by: nuts_3^nuts_2 | by: nuts_3^nuts_2^CNTR_CODE |
| FE: CNTR_CODE | X | |||||
| FE: nuts_3 | X | X | X | |||
| FE: nuts_3^nuts_2 | X | |||||
| FE: nuts_2 | X | X | ||||
| FE: nuts_3^nuts_2^CNTR_CODE | X | |||||
| + p |
Second way
First, we find all municipalities through which a road stretches:
numbers <- st_intersects(final, roads2) |>
as.data.frame() |>
select(row.id) |>
pull() |>
unique()
road_municipalities <- final |> filter(is.element(row_number(), numbers))
Then we find out what their neighbours are, required that they do not themselves have a road..
numbers2 <- st_touches(final, road_municipalities) |>
as.data.frame() |>
select(row.id) |>
pull() |>
unique()
neighbors_of_rm <- final |> filter(is.element(row_number(), numbers2) & !is.element(row_number(), numbers))
.. and create a “treatment” variable based on this:
final_experiment <- final |>
mutate(treatment = if_else(is.element(LAU_ID, road_municipalities$LAU_ID), 1,
if_else(is.element(LAU_ID, neighbors_of_rm$LAU_ID), 0,
NA_real_)))
Let’s now analyze and see whether there is a difference in population density between treatment and control groups:
model1 <- fixest::feols(POP_DENS_2019 ~ treatment, final_experiment)
model2 <- fixest::feols(POP_DENS_2019 ~ treatment | nuts_3, final_experiment)
model3 <- fixest::feols(POP_DENS_2019 ~ treatment | nuts_3 + nuts_2, final_experiment)
model4 <- fixest::feols(POP_DENS_2019 ~ treatment | nuts_3 + nuts_2 + CNTR_CODE, final_experiment)
model5 <- fixest::feols(POP_DENS_2019 ~ treatment | nuts_3^nuts_2, final_experiment)
model6 <- fixest::feols(POP_DENS_2019 ~ treatment | nuts_3^nuts_2^CNTR_CODE, final_experiment)
modelsummary(list(model1, model2,
model3, model4,
model5, model6), stars = T)
| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 | |
|---|---|---|---|---|---|---|
| (Intercept) | 241.407*** | |||||
| (11.343) | ||||||
| treatment | 49.451** | 60.412*** | 60.412*** | 60.412*** | 60.412*** | 60.412*** |
| (18.414) | (12.715) | (12.731) | (12.731) | (12.715) | (12.715) | |
| Num.Obs. | 13415 | 13410 | 13410 | 13410 | 13410 | 13410 |
| R2 | 0.001 | 0.664 | 0.664 | 0.664 | 0.664 | 0.664 |
| R2 Adj. | 0.000 | 0.658 | 0.658 | 0.658 | 0.658 | 0.658 |
| R2 Within | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | |
| R2 Within Adj. | 0.002 | 0.002 | 0.002 | 0.002 | 0.002 | |
| RMSE | 1034.85 | 599.63 | 599.63 | 599.63 | 599.63 | 599.63 |
| Std.Errors | IID | by: nuts_3 | by: nuts_3 | by: nuts_3 | by: nuts_3^nuts_2 | by: nuts_3^nuts_2^CNTR_CODE |
| FE: CNTR_CODE | X | |||||
| FE: nuts_3 | X | X | X | |||
| FE: nuts_3^nuts_2 | X | |||||
| FE: nuts_2 | X | X | ||||
| FE: nuts_3^nuts_2^CNTR_CODE | X | |||||
| + p |
Conclusion
It seems the Roman Empire’s heritage lasts until this day. Areas in which the Romans built roads are still more densely populated almost 2000 years after their construction, indicating an extreme path dependency. Of course, there is a lot of omitted variable bias, but arguably, a lot of it is taken away by conditioning on pretty granular NUTS-3 levels already. In the future I should probably look at this more seriously, and probably also read a book on Roman and, possibly, Medieval history. :) Thanks for reading!
- Posted on:
- February 15, 2023
- Length:
- 10 minute read, 2037 words
- See Also: